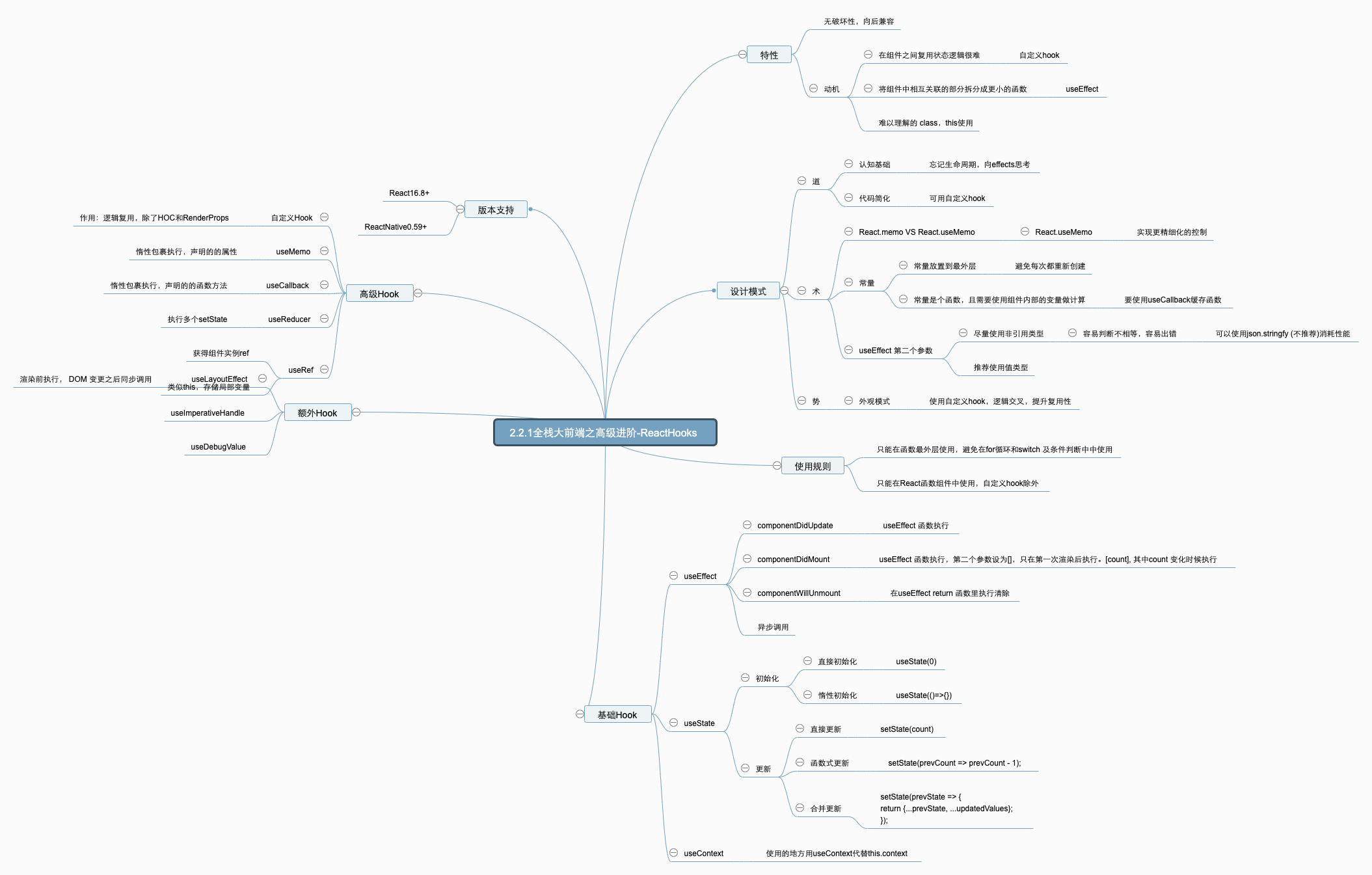
# 规则限制
只在 React 函数中调用 Hook;
不要在循环、条件或嵌套函数中调用 Hook。
# 为何不要在循环、条件或嵌套函数中调用 Hook?
- 从源码调用流程看原理:Hooks 的正常运作,在底层依赖于顺序链表
这里强调“源码流程”而非“源码”,主要有两方面的考虑:
React-Hooks 在源码层面和 Fiber 关联十分密切,我们目前仍然处于基础夯实阶段,对 Fiber 机制相关的底层实现暂时没有讨论,盲目啃源码在这个阶段来说没有意义;
原理 !== 源码,阅读源码只是掌握原理的一种手段,在某些场景下,阅读源码确实能够迅速帮我们定位到问题的本质(比如 React.createElement 的源码就可以快速帮我们理解 JSX 转换出来的到底是什么东西);而 React-Hooks 的源码链路相对来说比较长,涉及的关键函数 renderWithHooks 中“脏逻辑”也比较多,整体来说,学习成本比较高,学习效果也难以保证。
综上所述,这里我不会精细地贴出每一行具体的源码,而是针对关键方法做重点分析。同时我也不建议你在对 Fiber 底层实现没有认知的前提下去和 Hooks 源码死磕。对于搞清楚“Hooks 的执行顺序为什么必须一样”这个问题来说,重要的并不是去细抠每一行代码到底都做了什么,而是要搞清楚整个调用链路是什么样的。如果我们能够理解 Hooks 在每个关键环节都做了哪些事情,同时也能理解这些关键环节是如何对最终的渲染结果产生影响的,那么理解 Hooks 的工作机制对于你来说就不在话下了
以 useState 为例,分析 React-Hooks 的调用链路 首先要说明的是,React-Hooks 的调用链路在首次渲染和更新阶段是不同的,这里我将两个阶段的链路各总结进了两张大图里,我们依次来看。首先是首次渲染的过程,请看下图

在这个流程中,useState 触发的一系列操作最后会落到 mountState 里面去,所以我们重点需要关注的就是 mountState 做了什么事情。以下我为你提取了 mountState 的源码:
// 进入 mounState 逻辑
function mountState(initialState) {
// 将新的 hook 对象追加进链表尾部
var hook = mountWorkInProgressHook();
// initialState 可以是一个回调,若是回调,则取回调执行后的值
if (typeof initialState === 'function') {
// $FlowFixMe: Flow doesn't like mixed types
initialState = initialState();
}
// 创建当前 hook 对象的更新队列,这一步主要是为了能够依序保留 dispatch
const queue = hook.queue = {
last: null,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: (initialState: any),
};
// 将 initialState 作为一个“记忆值”存下来
hook.memoizedState = hook.baseState = initialState;
// dispatch 是由上下文中一个叫 dispatchAction 的方法创建的,这里不必纠结这个方法具体做了什么
var dispatch = queue.dispatch = dispatchAction.bind(null, currentlyRenderingFiber$1, queue);
// 返回目标数组,dispatch 其实就是示例中常常见到的 setXXX 这个函数,想不到吧?哈哈
return [hook.memoizedState, dispatch];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
从这段源码中我们可以看出,mounState 的主要工作是初始化 Hooks。在整段源码中,最需要关注的是 mountWorkInProgressHook 方法,它为我们道出了 Hooks 背后的数据结构组织形式。以下是 mountWorkInProgressHook 方法的源码
function mountWorkInProgressHook() {
// 注意,单个 hook 是以对象的形式存在的
var hook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null
};
if (workInProgressHook === null) {
// 这行代码每个 React 版本不太一样,但做的都是同一件事:将 hook 作为链表的头节点处理
firstWorkInProgressHook = workInProgressHook = hook;
} else {
// 若链表不为空,则将 hook 追加到链表尾部
workInProgressHook = workInProgressHook.next = hook;
}
// 返回当前的 hook
return workInProgressHook;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
到这里可以看出,hook 相关的所有信息收敛在一个 hook 对象里,而 hook 对象之间以单向链表的形式相互串联。
接下来我们再看更新过程的大图:

根据图中高亮部分的提示不难看出,首次渲染和更新渲染的区别,在于调用的是 mountState,还是 updateState。mountState 做了什么,你已经非常清楚了;而 updateState 之后的操作链路,虽然涉及的代码有很多,但其实做的事情很容易理解:按顺序去遍历之前构建好的链表,取出对应的数据信息进行渲染。
我们把 mountState 和 updateState 做的事情放在一起来看:mountState(首次渲染)构建链表并渲染;updateState 依次遍历链表并渲染。
看到这里,你是不是已经大概知道怎么回事儿了?没错,hooks 的渲染是通过“依次遍历”来定位每个 hooks 内容的。如果前后两次读到的链表在顺序上出现差异,那么渲染的结果自然是不可控的。
这个现象有点像我们构建了一个长度确定的数组,数组中的每个坑位都对应着一块确切的信息,后续每次从数组里取值的时候,只能够通过索引(也就是位置)来定位数据。也正因为如此,在许多文章里,都会直截了当地下这样的定义:Hooks 的本质就是数组。但读完这一课时的内容你就会知道,Hooks 的本质其实是链表。
接下来我们把这个已知的结论还原到 PersonalInfoComponent 里去,看看实际项目中,变量到底是怎么发生变化的。
# Hooks
useState
useEffect
useMemo
# 问答环节
- React Hooks 的 useState 为什么不能放到条件语句?
Hooks 的本质其实是一个有序链表
hooks 的渲染是通过“依次遍历”来定位每个 hooks 内容的。如果前后两次读到的链表在顺序上出现差异,那么渲染的结果自然是不可控的